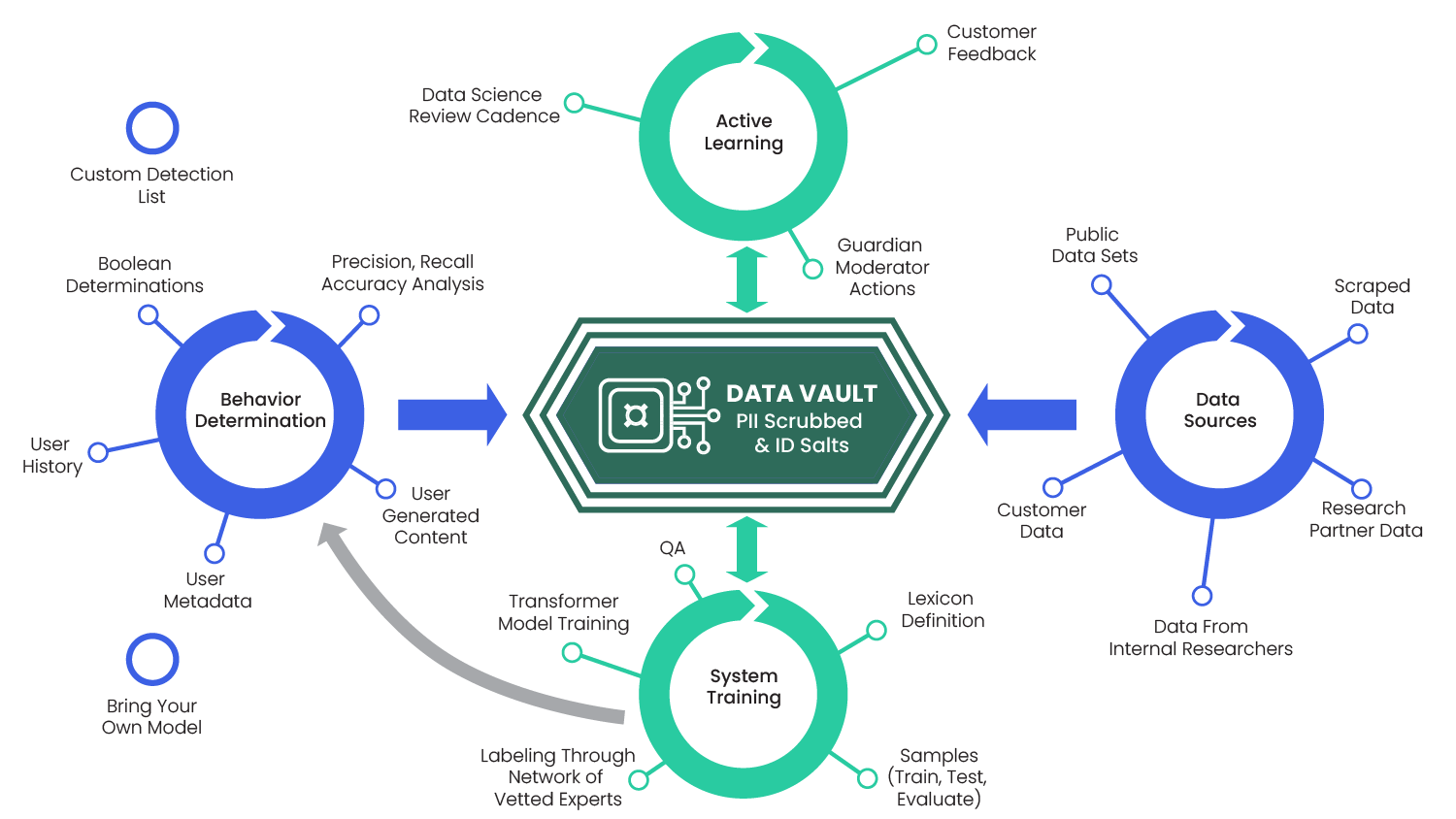
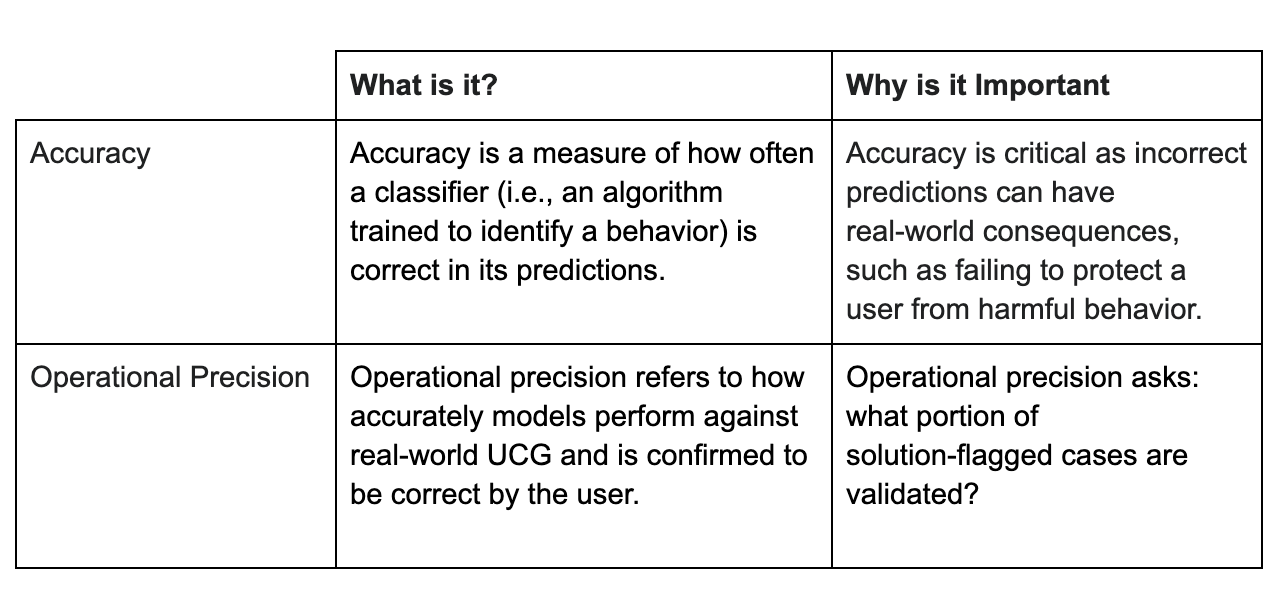
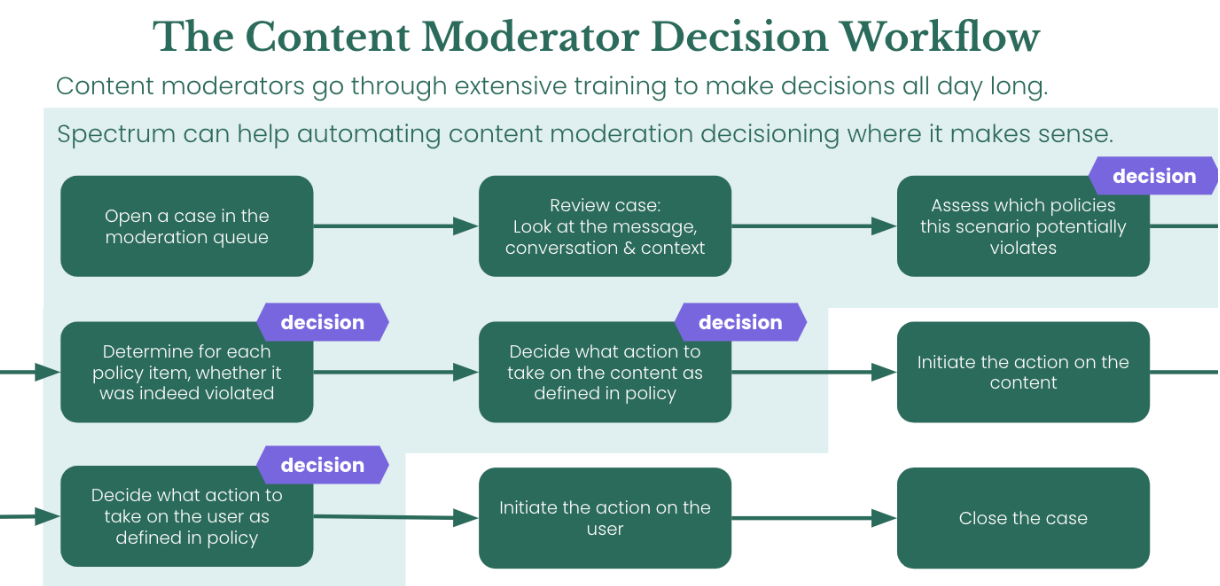
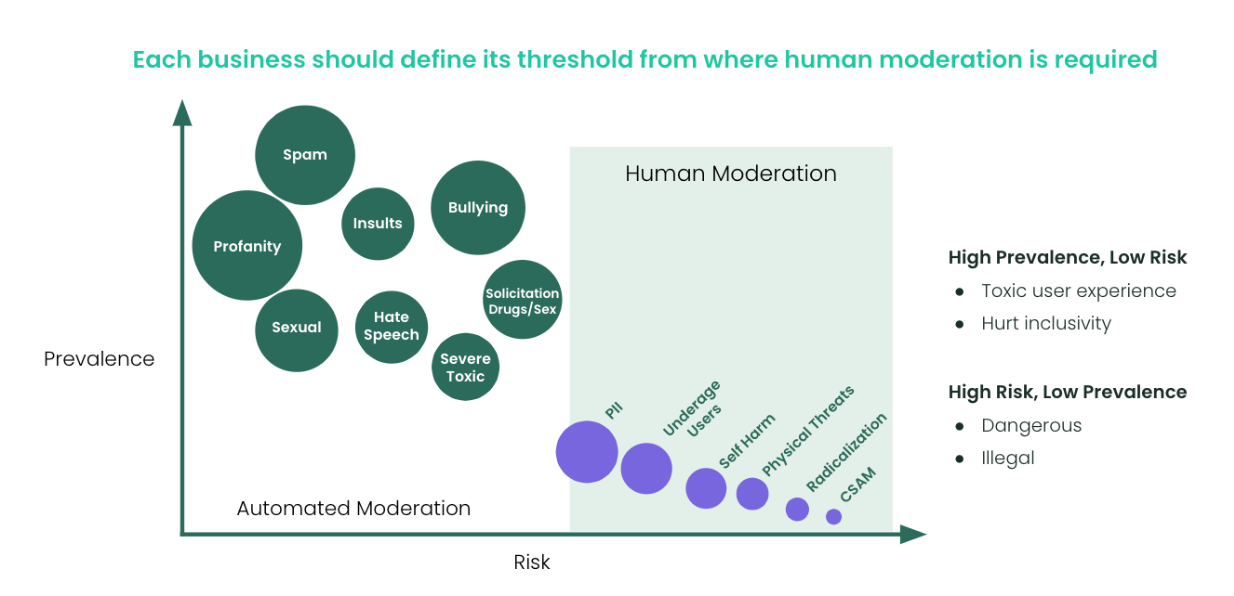
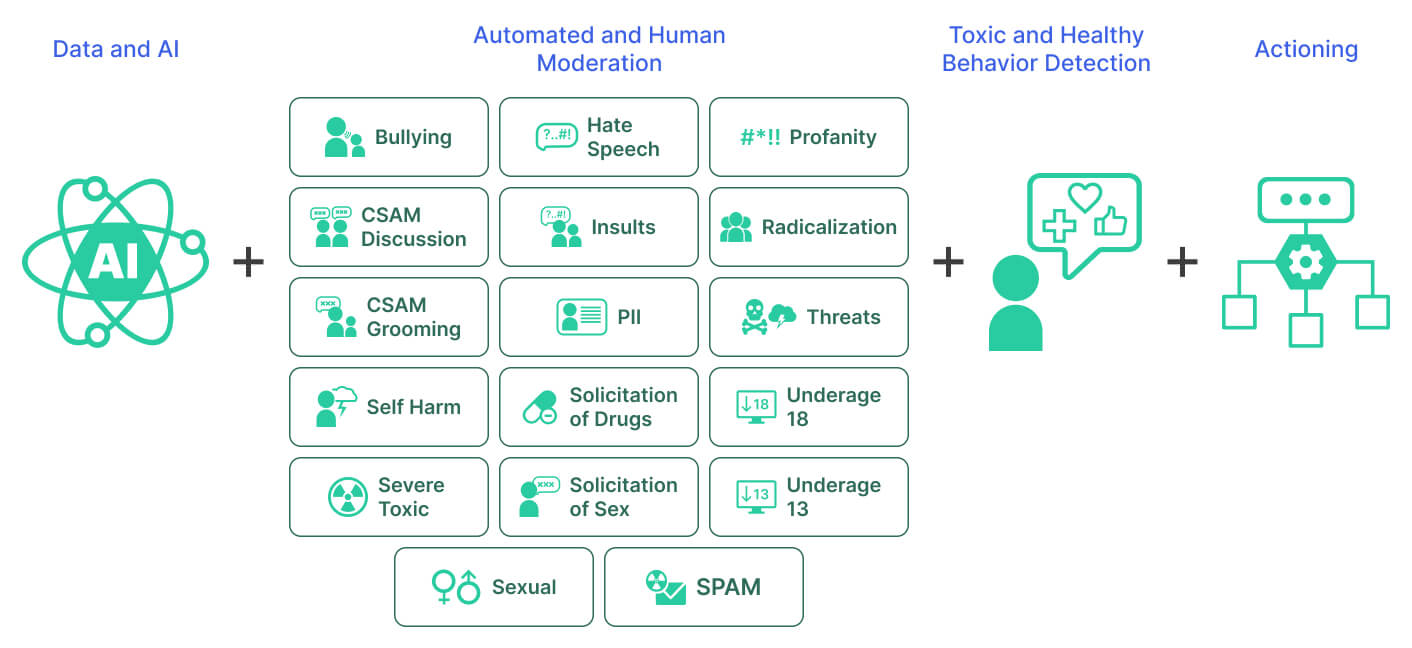
Spectrum Labs AI detection solutions can help Trust & Safety teams detect individual behaviors, such as hate speech, radicalization, and threats, but are those one-off issues? Or are these cases indicative of a larger problem on your platform?
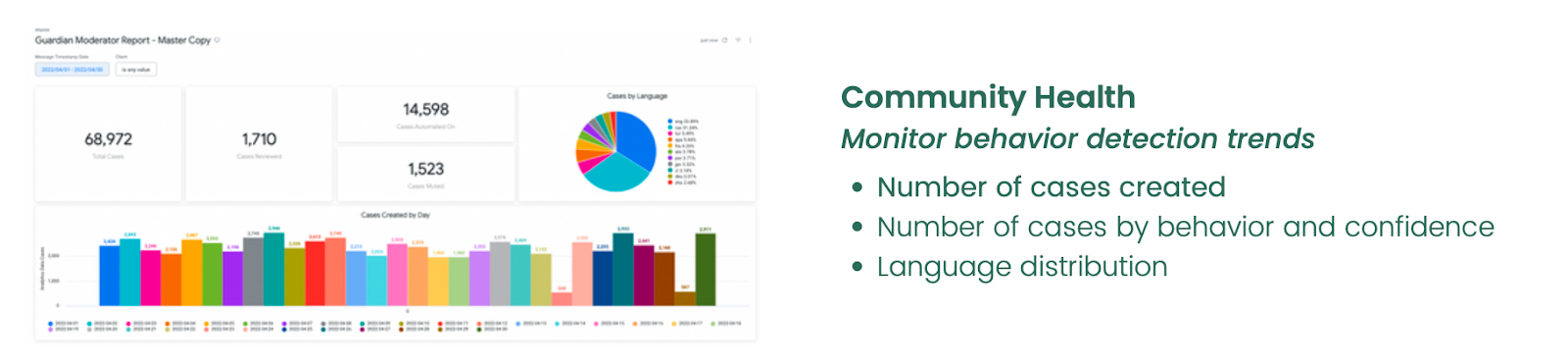
To help clients answer that question, we combine metrics about top toxic and at-risk users with other factors, such behaviors, languages, community areas, and user attributes. This allows you to see at a glance the frequency of infractions and detect behavioral trends that may occur on your platform.
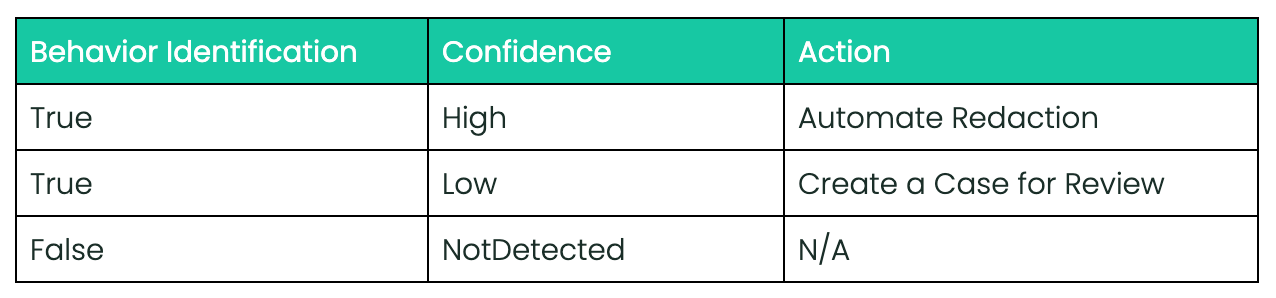
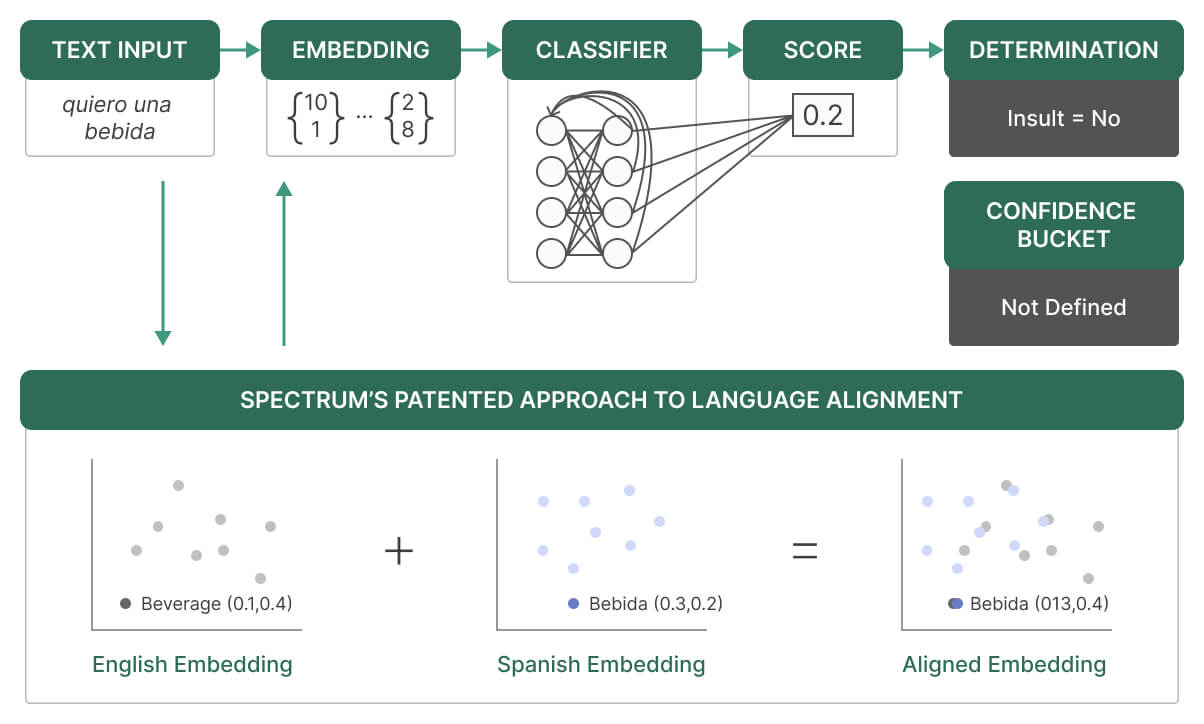
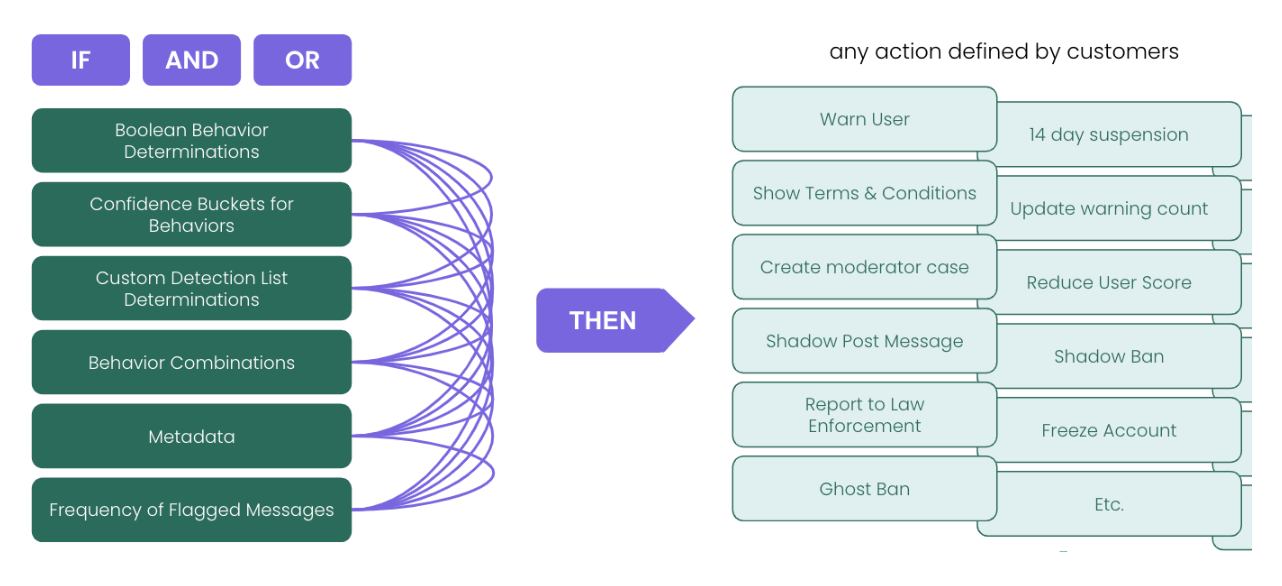
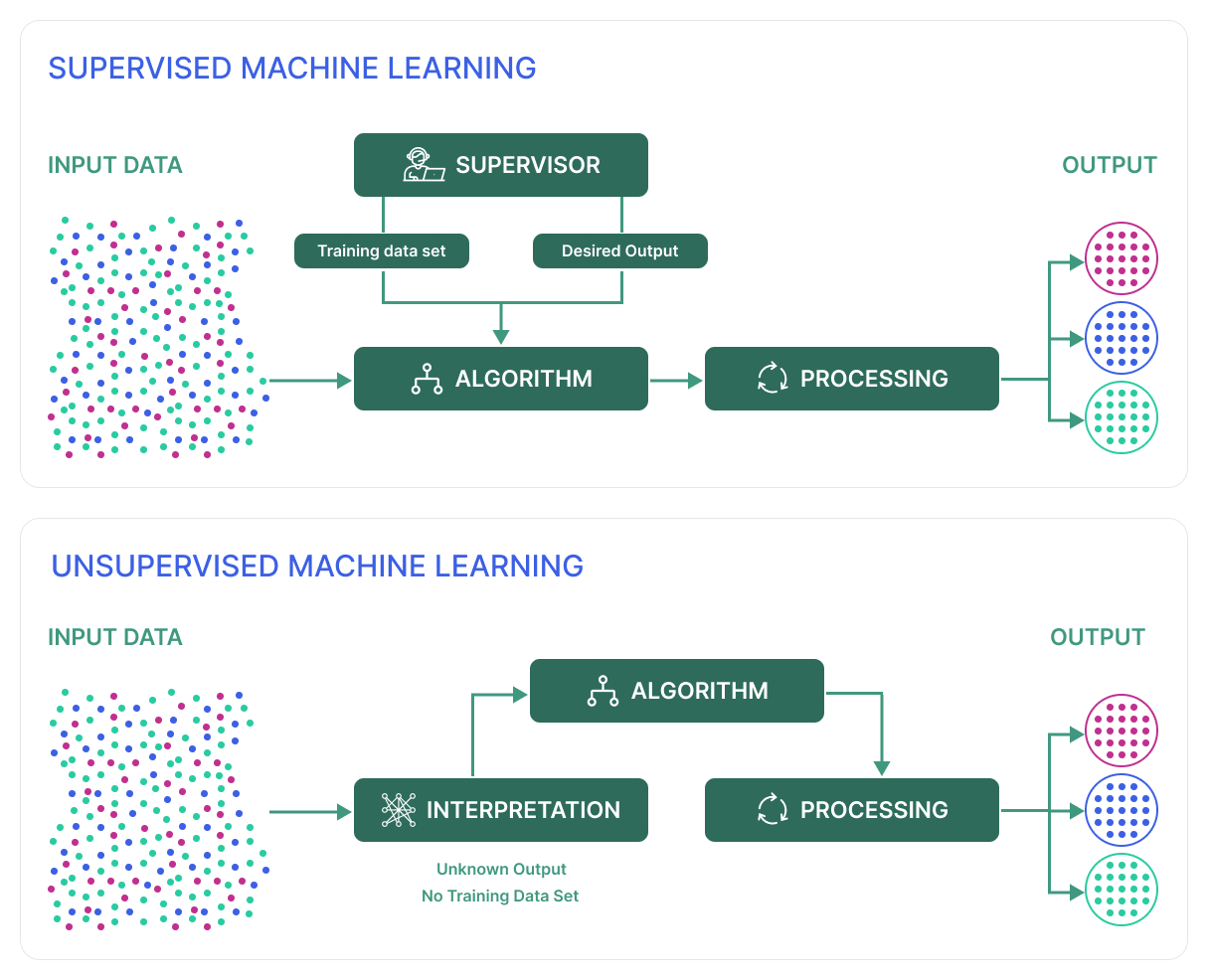
We deploy a variety of tactics to identify behavior trends. The first is an AI-driven behavioral detection feature. When a user creates text content, Spectrum's API validates it against behavior solutions. The API returns results for the content, including which behaviors were flagged and confidence levels.
Our dashboards allow you to filter by behaviors, time ranges, content categories and more. You can also choose how to visualize the data and export it for distribution or further analysis, such as overlaying metrics with your other key performance indicators to identify influencers, analytics, and insights help you make better decisions about how to shape your community.
Spectrum Labs can help you:
- Identify which problems or chatroom to address first
- Learn which users drive toxicity
- Understand how behaviors interrelate
- Inform policies for different languages
- See emerging patterns to address early.
These insights allow you to identify the types of problems that happen on your platform so that you can provide any additional training for your moderators, as well as update your community policies as you need to.
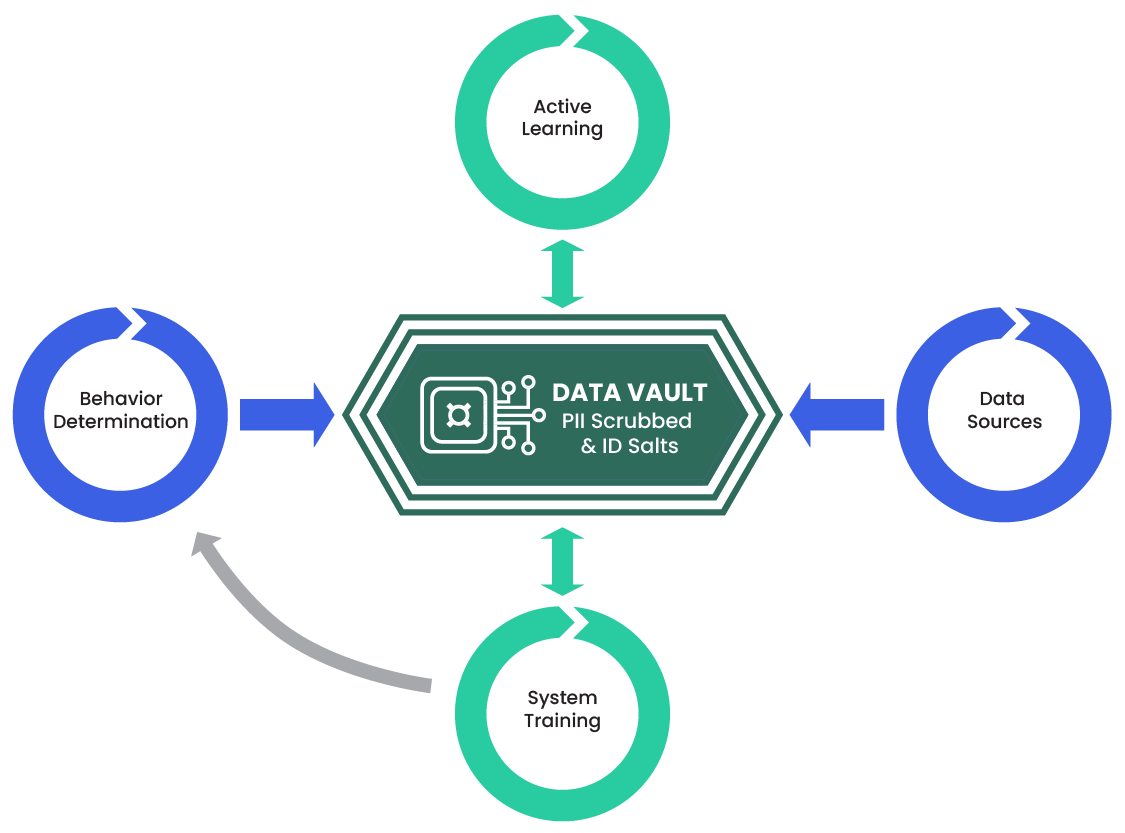
All three product features – user reputation score, user-level moderation, and behavior detection trends – are fully privacy compliant.

.jpg)